Performance notes for v0.0.4b1#
This page summarizes local release-validation measurements for the native CPU backend as of v0.0.4b1. The numbers show direction and scale for the paths that were optimized. They are examples from one machine, not portable performance guarantees.
Reference machine and timing rules#
The reference machine was an Apple MacBook Pro with an Apple M5 chip. The
benchmark metadata reported 10 hardware workers. The selected MLX device was
CPU, and the native-extension build used for these runs did not have
Accelerate solver support available. Unless stated otherwise, values were
float32 and sparse indices were int32.
The baseline means the pre-optimization native CPU behavior used during v0.0.4b1 release validation. It is a code-path baseline, not a claim about a fresh wheel installed from a package index.
All sparse timings force real work:
CSR/CSC outputs evaluate
data,indices, andindptr.COO outputs evaluate
data,row, andcol.Dense outputs use
mx.eval(result).
Warning
SciPy comparisons on this page are timing context only. Several mlx-sparse measurements use four or ten native CPU workers, while the SciPy reference timings are whatever the local SciPy build used by default on the same machine. That is not a strict single-thread apples-to-apples comparison.
Warning
Single-thread native CPU performance still trails SciPy on many solver and sparse-dense cases. The SciPy ratio tables are included to make that visible, not to imply broad parity with mature Sparse BLAS or sparse solver implementations.
Ratio definitions#
baseline/current means baseline median time divided by the current
mlx-sparse median time. A value above 1.0x means the current native CPU
path used less time on that benchmark case.
SciPy/native means SciPy median time divided by mlx-sparse median time.
The ratio is useful context, but it mixes library implementations, threading
policies, and solver maturity.
Benchmark matrix catalog#
Sparse performance is matrix-structure dependent, so the benchmark shape is part of every result.
Benchmark family |
Matrices |
Sparsity |
Workers |
|---|---|---|---|
Same-format SpGEMM |
CSR/COO/CSC square products, sizes |
Target nonzeros per row |
Serial control: one CPU worker and SpGEMM parallel disabled. Parallel run: four SpGEMM workers. |
CSR sparse-dense small cases |
Matvec: |
Densities about |
One CPU worker. |
CSR sparse-dense large cases |
Matvec: |
Densities |
One and four CPU workers. |
COO/CSC batched dense products |
COO/CSC matvec and matmul, sizes |
Families: uniformly short rows, imbalanced rows, banded,
diagonal-dominant, output-density sweeps. Target nonzeros per row
|
One-worker serial control and four CPU workers. |
|
Dense-to-CSR inputs, sizes |
Target output nonzeros per row |
One and four CPU workers. |
Scalar reductions |
CSR/COO/CSC trace plus CSR sparse |
|
One and four CPU workers. |
Direct factorization |
Native Cholesky and LU on sizes |
Target nonzeros per row |
One CPU worker. |
Repeated explicit-factor solves |
Same matrices as direct factorization. RHS counts |
Target nonzeros per row |
One CPU worker for the production solve-only summary. Solver parallelism disabled by default. |
1/4/10 worker probe |
CSR @ CSR: |
Densities: CSR LHS |
One, four, and ten CPU workers. |
Selected native CPU speedups#
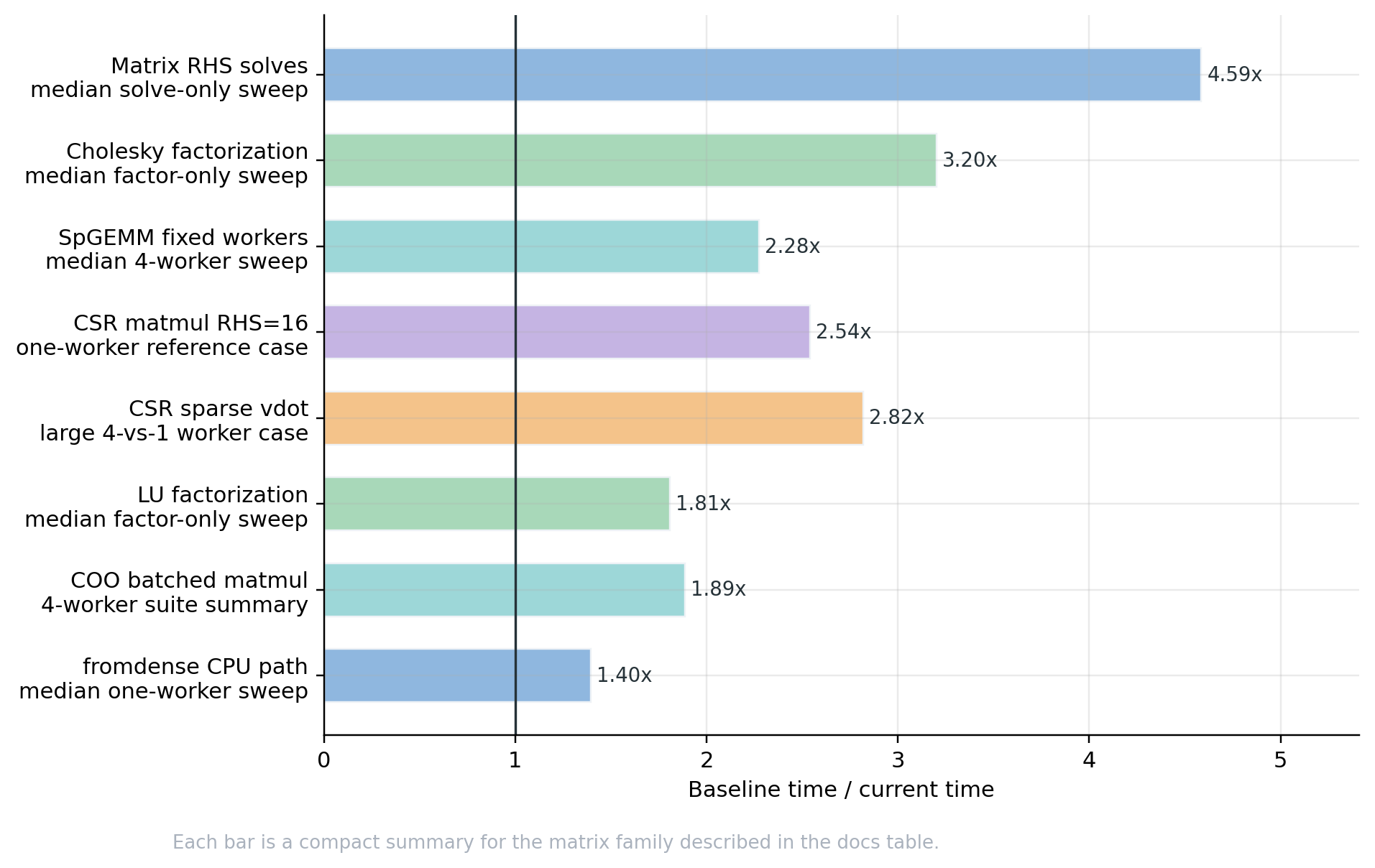
Family |
Summary ratio |
Matrix and timing scope |
|---|---|---|
Same-format SpGEMM |
|
Median four-worker ratio over 99 CSR/COO/CSC square-product cases from the SpGEMM catalog above. |
Serial SpGEMM final-writer |
|
Median one-worker ratio over 285 SpGEMM cases. Exact-cancellation
cases had median |
CSR sparse-dense |
|
One-worker small CSR matvec and CSR matmul RHS=16 reference cases. |
COO/CSC batched dense products |
|
Four-worker operation summaries over the batched COO/CSC catalog. |
|
|
Median one-worker dense-to-CSR constructor ratio over the |
Matrix-RHS repeated solves |
|
One-worker solve-only median over the direct-solve matrix-RHS catalog. |
Direct factorization |
|
One-worker factor-only medians over the direct-factorization catalog. |
Scalar reductions |
|
Large CSR sparse |
SciPy timing context#
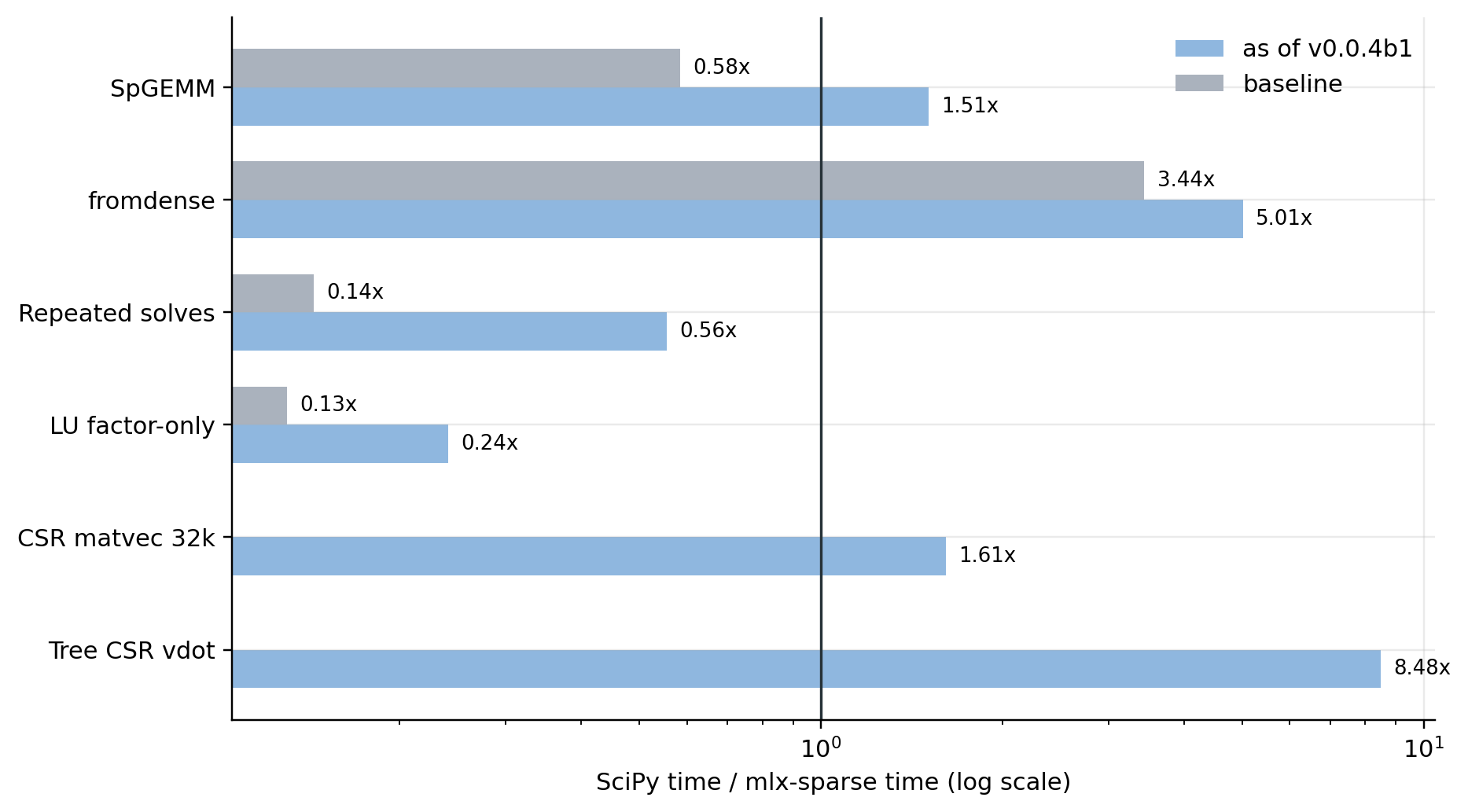
Read this chart together with the warnings above. Ratios use the local SciPy reference timings from the same benchmark run, but worker counts and implementation strategies differ.
Case |
Baseline |
As of v0.0.4b1 |
Matrix and worker details |
|---|---|---|---|
Same-format SpGEMM |
|
|
Median SciPy/native ratio for the SpGEMM sweep. The v0.0.4b1 value is the four-worker SpGEMM run. |
|
|
|
Median SciPy/native ratio for one-worker dense-to-CSR cases with sizes
|
Matrix-RHS repeated solves |
|
|
One-worker solve-only direct-solve sweep with RHS counts through
|
LU factor-only |
|
|
One-worker native LU factorization sweep. SciPy reference is SuperLU. |
CSR matvec, 32k |
n/a |
|
|
CSR sparse |
n/a |
|
|
Thread-count sensitivity#
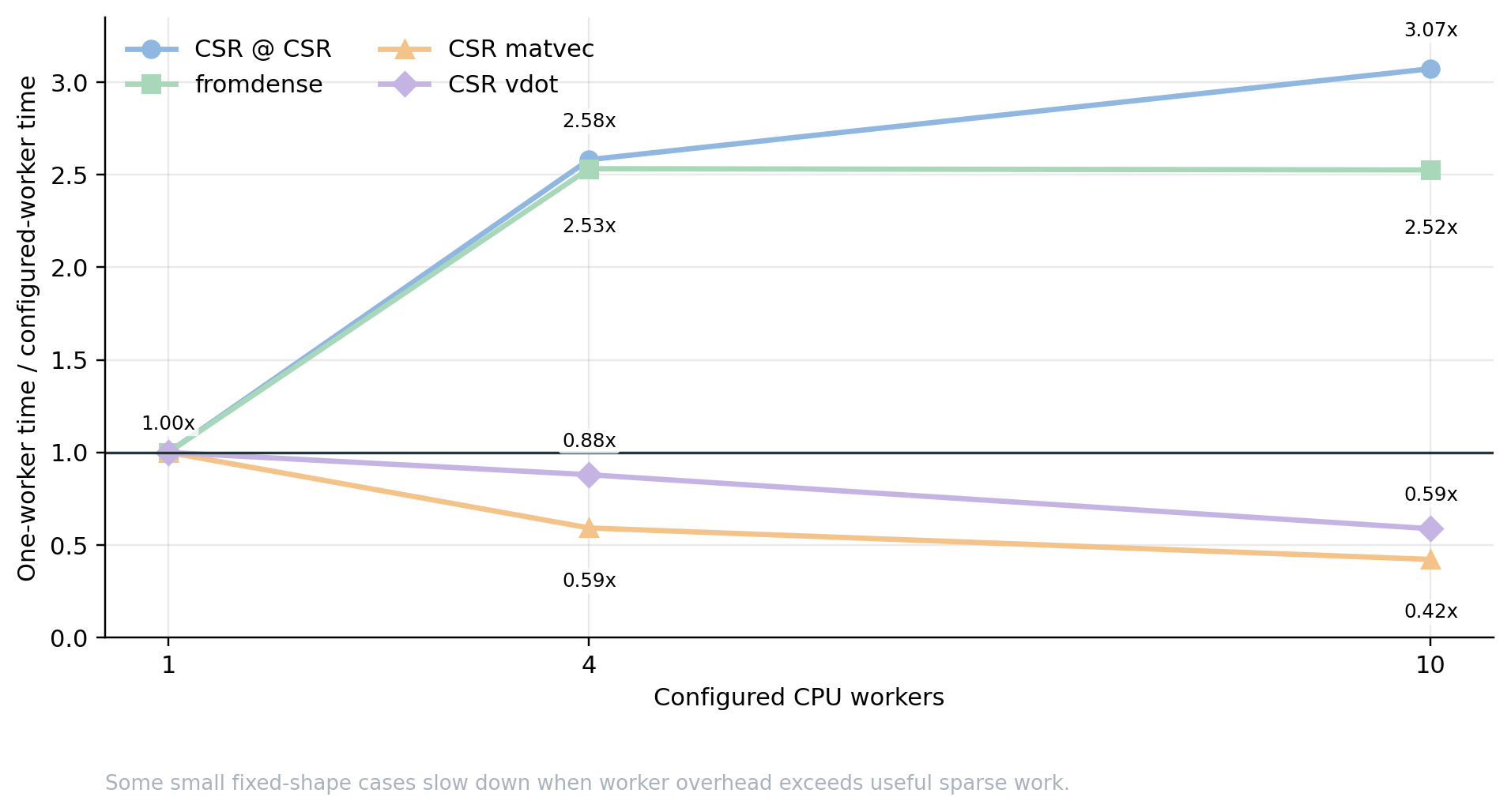
The worker-count probe uses evaluated medians on the same M5 machine. Values
below 1.0x mean the multi-worker setting took longer than one worker for
that small case.
Operation |
1 worker |
4 workers |
10 workers |
Matrix details |
|---|---|---|---|---|
CSR @ CSR |
|
|
|
|
|
|
|
|
|
CSR matvec |
|
|
|
|
CSR sparse |
|
|
|
Same |
Sparse-sparse products#
As of v0.0.4b1, same-format CSR/COO/CSC host SpGEMM uses deterministic
output-row or output-column ownership. The sweep used square matrices of
sizes 512, 2048, and 8192 with the families and sparsities listed
in the catalog.
Operation |
4-worker summary vs serial |
4-worker summary vs SciPy |
Notes |
|---|---|---|---|
CSR @ CSR |
|
|
Row-owned output partitions. |
COO @ COO |
|
|
Row-owned COO output assembly. |
CSC @ CSC |
|
|
Column-owned output partitions. |
Overall median |
|
|
99 records. Smallest/lightest cases include worker overhead. |
Size matters. The four-worker summary ratios versus the serial control were:
Format |
|
|
|
|---|---|---|---|
CSR |
|
|
|
COO |
|
|
|
CSC |
|
|
|
Fixed-shape sparse-dense products#
CSR row-owned products were tested on the small and large cases below.
Case |
Matrix |
Before |
As of v0.0.4b1 |
Ratio |
|---|---|---|---|---|
CSR matvec, one worker |
|
|
|
|
CSR matmul RHS=16, one worker |
|
|
|
|
CSR matvec, one worker |
|
n/a |
|
n/a |
CSR matvec, four workers |
Same 32k matvec matrix. |
one-worker current |
|
|
CSR matmul RHS=16, one worker |
|
n/a |
|
n/a |
CSR matmul RHS=16, four workers |
Same 32k matmul matrix. |
one-worker current |
|
|
COO/CSC batched dense products use disjoint batch-slab ownership as of
v0.0.4b1. The sweep used batch size 4, RHS width 8 for matmul, sizes
512 through 32768, and target nonzeros per row 2, 8, 32.
Operation |
Four-worker summary vs serial |
SciPy/native context |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
Non-batched COO/CSC forward dense products remain serial because they scatter into shared dense output rows.
Constructors, conversions, and canonicalization#
The CPU fromdense path scans dense rows directly into canonical CSR
buffers as of v0.0.4b1. The constructor sweep used sizes 512, 2048,
and 4096 with target output nonzeros per row 2, 8, and 32.
Case |
Worker setting |
Summary ratio vs staged CPU baseline |
SciPy/native context |
|---|---|---|---|
|
one worker |
|
|
|
four workers |
|
|
Immediate host assembly for compressed sum_duplicates was measured and
rejected. The staged count/prefix/fill implementation remains the production
CPU path because it was the better one-worker target in the measured sweep.
Format conversions and transposes were reworked for race-free parallelism with histogram/prefix/scatter or destination-owned partitions. Small conversions can remain overhead-bound, while larger conversion and constructor cases are the intended targets for deterministic worker-owned ranges.
Reductions and sparse scalar products#
The large scalar-reduction sweep used 4096 x 4096 matrices with
1,048,576 nonzeros and density 0.0625.
Operation |
1 worker |
4 workers |
Worker ratio |
SciPy/native context |
|---|---|---|---|---|
CSR trace |
|
|
|
|
COO trace |
|
|
|
|
CSC trace |
|
|
|
|
CSR sparse |
|
|
|
|
CSR sparse |
|
|
|
|
Some dense conversions and small scalar reductions remain limited by memory
traffic or launch overhead. In the large reduction sweep, CSC dense
conversion measured 0.72x versus the legacy conversion path and 0.49x
on the SciPy/native context ratio.
Direct factorization and repeated solves#
The direct-factorization work is single-threaded and storage-focused. It does not make natural-order Cholesky or LU numerically parallel.
Phase |
Native ratio |
SciPy/native context |
Matrix scope |
|---|---|---|---|
Cholesky factor-only |
|
no SciPy sparse Cholesky equivalent |
Banded/random SPD, sizes |
Cholesky factor-plus-solve |
|
no SciPy sparse Cholesky equivalent |
Same SPD sweep. |
Cholesky solve-only |
|
no SciPy sparse Cholesky equivalent |
Same SPD sweep. |
LU factor-only |
|
|
Banded/random SPD and general matrices, sizes |
LU factor-plus-solve |
|
|
Same LU sweep. |
LU solve-only |
|
|
Same LU sweep. |
By family, Cholesky factor-only medians were 1.995x on banded SPD and
6.275x on random SPD matrices. LU factor-only medians were 1.370x on
banded SPD, 1.490x on banded general, 2.405x on random SPD, and
2.348x on random general matrices.
Matrix-RHS repeated solves remove Python column loops. The sweep used RHS
counts 1, 2, 4, 8, 16, and 32.
Case |
Result |
|---|---|
Overall, one worker |
Median after/before ratio |
Cholesky |
Median ratio |
LU |
Median ratio |
SciPy/native context |
One-worker solve-only ratio moved from |
Measured but not adopted#
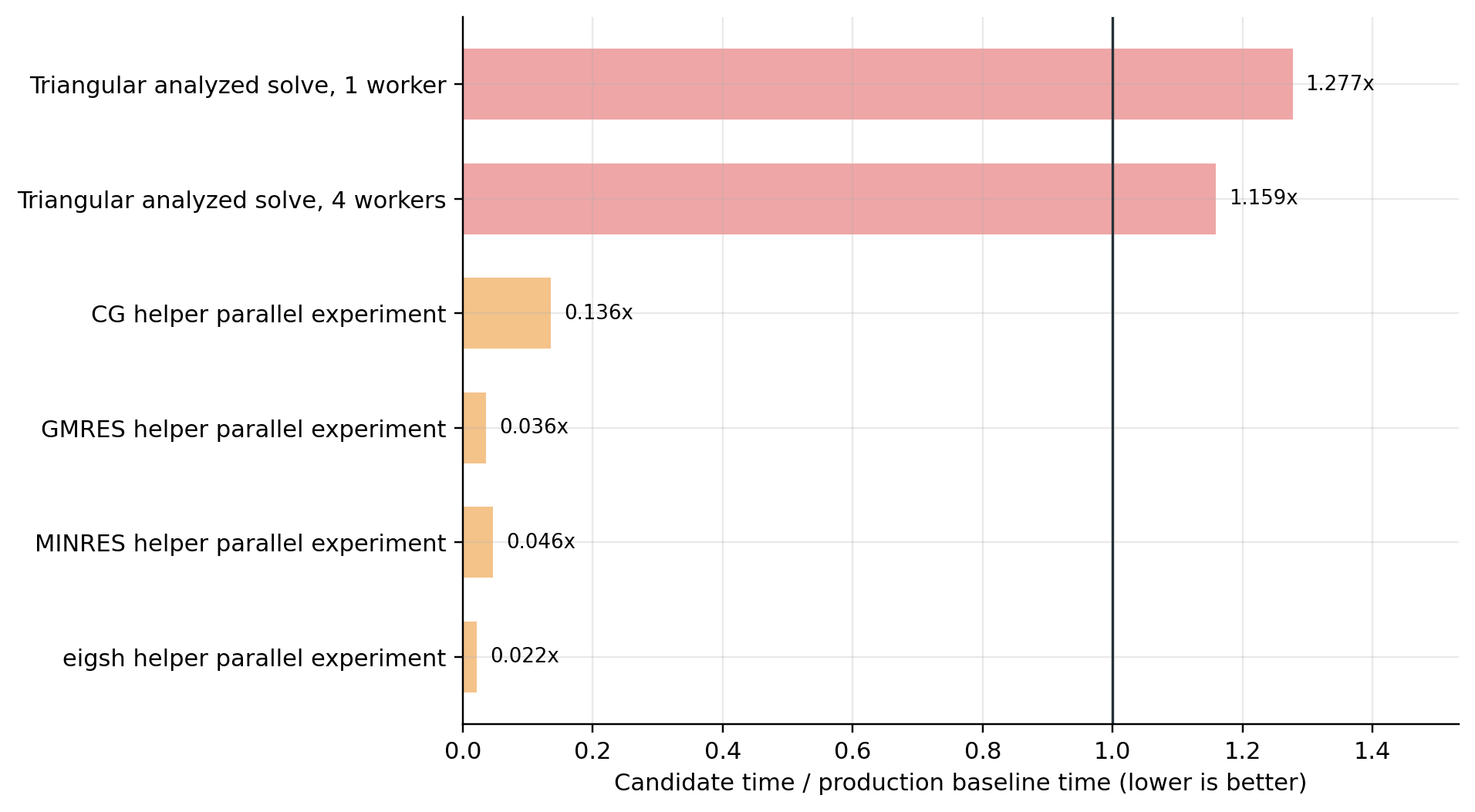
Several plausible HPC ideas were tested and rejected for production because they did not improve the relevant measured target:
Cached triangular diagonal positions and dependency-level scheduling were guarded by graph analysis and had row-order fallback, but the analyzed solve path measured
1.277xslower than baseline at one worker and1.159xslower at four solver workers.Iterative and spectral solver helper parallelism regressed the benchmark slice. For the
1024 x 1024solver check with3,120nonzeros, CG moved from0.0320 msto0.2358 ms, GMRES from0.4459 msto12.3347 ms, and MINRES from21.4326 msto463.6496 msunder the fixed-worker helper experiment.Immediate host assembly for compressed
sum_duplicatesdid not improve the one-worker target and was not shipped.Non-batched COO/CSC forward dense products stayed serial rather than using unsynchronized scatter writes.